FreedomAI Lab 媒体报道与研究脉络:从医疗大模型到多模态智能体
基于机器之心、量子位、PaperWeekly 等公开报道与项目链接,梳理 CUHKSZ FreedomAI Lab 在开放医疗智能、多模态长上下文、社会模拟与移动智能体方向的研究进展。
本文以 FreedomAI Lab 的视角重新整理这些公开报道。文中媒体图示均保留来源署名;图片来自对应报道页面,版权归原媒体与原作者所有。完整原文和项目链接见文末来源索引。
Open Medical Intelligence
FreedomAI Lab 最早被广泛关注的一条主线,是让医学大模型更开放、更可评测、更贴近中文真实场景。媒体对 HuatuoGPT 的报道集中在两个问题上:如何把中文医疗问答、医生反馈和语言模型能力结合起来;以及如何让模型评价不止停留在单一分数,而能接受更接近临床沟通的检验。
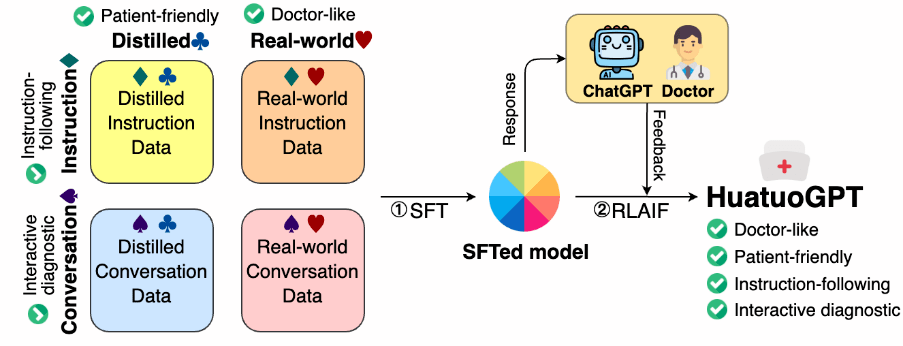
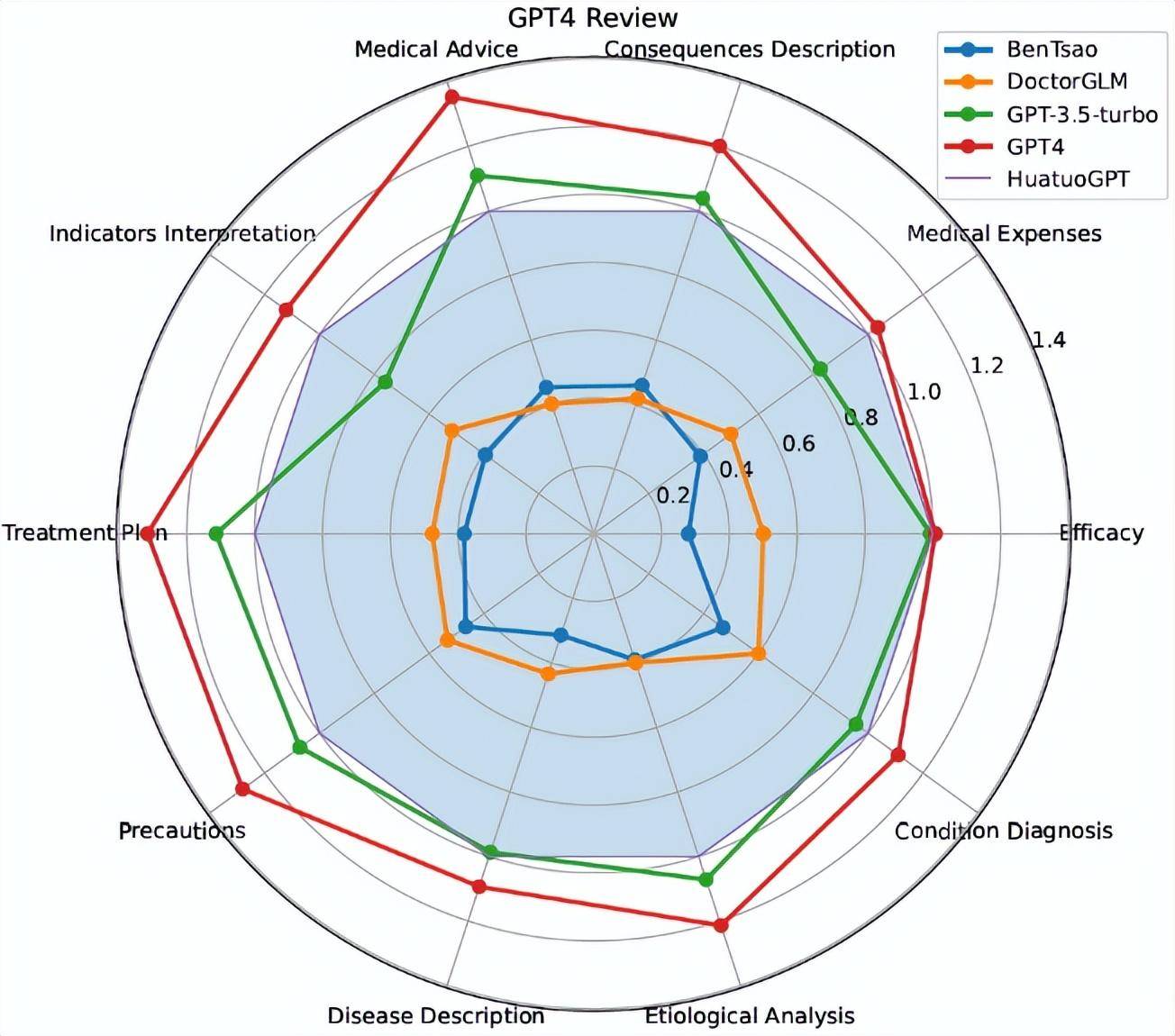
在 HuatuoGPT 之后,我们继续推动中文医疗大模型的系统化评估。CMB 的出发点是把医学考试、医学知识与模型能力评测纳入更完整的中文医疗基准框架。PaperWeekly 将其放在“SuperAlignment in Medical Science”的语境下讨论:医疗智能不只需要生成答案,也需要可追踪、可比较、可复现的评价基准。

这条路线后来延展到 HuatuoGPT-II、HuatuoGPT-o1、HuatuoGPT-3 和更多医学视觉模型。对我们而言,“开放医疗智能”不是单个模型的发布,而是一套连续的基础设施:数据、评测、模型、推理与社区反馈共同迭代。
HuatuoGPT-II HuatuoGPT-o1 HuatuoGPT-3 medical-o1 reasoning SFT
Open Dialogue and Evaluation
另一条媒体持续关注的线索,是开源对话能力和评测方法。机器之心报道 Phoenix / Chimera 时,强调了用 GPT-4 参与模型评测的实验范式,也介绍了港中深团队在 LLMZoo 方向的开放工作。我们希望把“会说多语言、能接受评价、可供社区复现”的模型基础能力,做成公共资源。

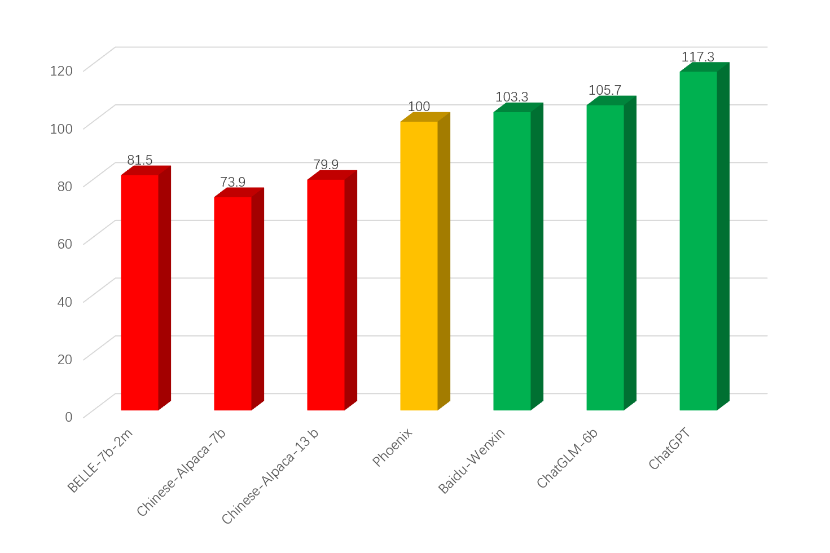
围绕对话数据,我们也探索了 SocraticChat / PlatoLM:用苏格拉底式提问构造更高质量的对话训练信号,让开源模型从 ChatGPT 风格的对话中学习更稳健的表达与追问能力。PaperWeekly 的报道把这个工作放在“如何更好蒸馏对话能力”的问题上,这也是我们持续关心的方向:模型不只是回答,还要学会澄清、追问和组织复杂信息。

量子位关于大模型红队攻击与对比界面的报道,则从另一个角度提醒我们:模型能力越强,越需要可交互、可复核的对比工具。该报道文末注明,模型对比界面由香港中文大学(深圳)王本友教授团队和魔搭社区共同开发。这样的工具型工作常常不像模型发布那样显眼,却是安全评测、对齐研究和社区协作不可缺少的一环。
Multimodal Long Context
LongLLaVA 是我们在多模态方向的重要尝试之一。机器之心和 PaperWeekly 都把它的关键词概括为“混合架构”和“单卡千图推理”:它把 Mamba 与 Transformer 的长序列优势结合起来,面向需要大量图像输入的多模态场景做效率扩展。


从医疗视觉问答到多图推理,长上下文多模态模型的难点并不只是“能放下更多图片”。真正的问题在于:如何在有限显存和推理时间内,把跨图关系、视觉细节和语言推理连接起来。LongLLaVA 是这个问题的一块拼图,也为后续多模态 Agent、医学视觉和长程交互场景提供了基础。
Agents and Simulated Worlds
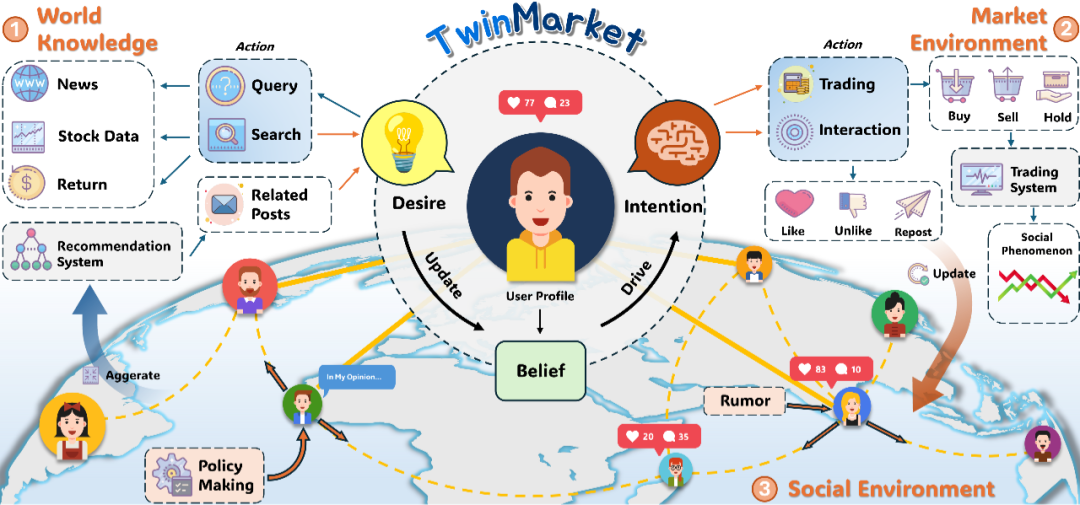
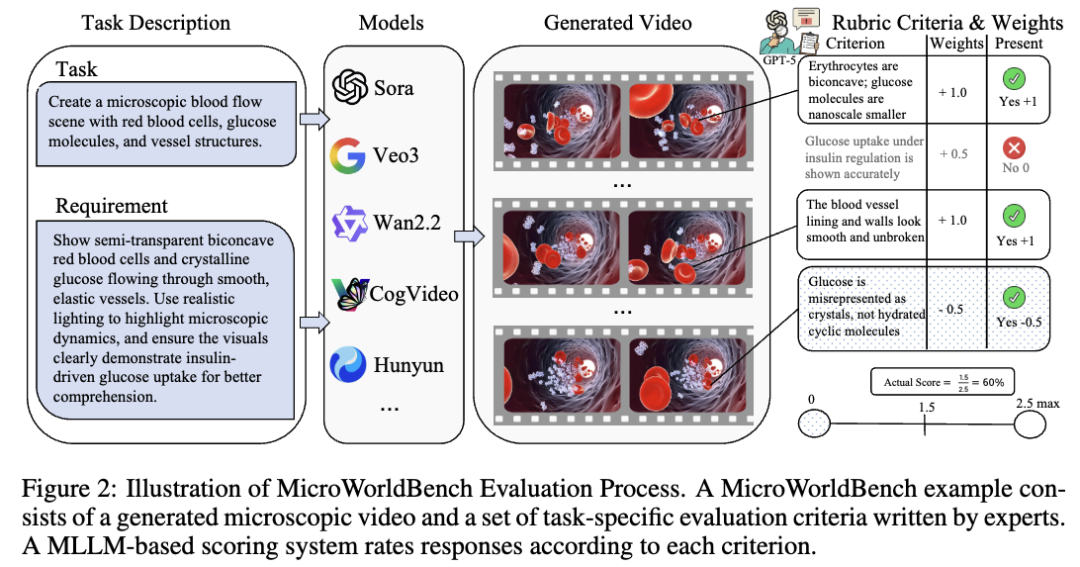
当模型进入更开放的真实任务,我们开始关注“环境”。TwinMarket 和 MicroVerse 都是这个问题的不同侧面:前者用大量虚拟投资者重现金融市场中的行为与涌现现象,后者探索微观世界模型,让 AI 能模拟肉眼不可见、但规律复杂的环境。
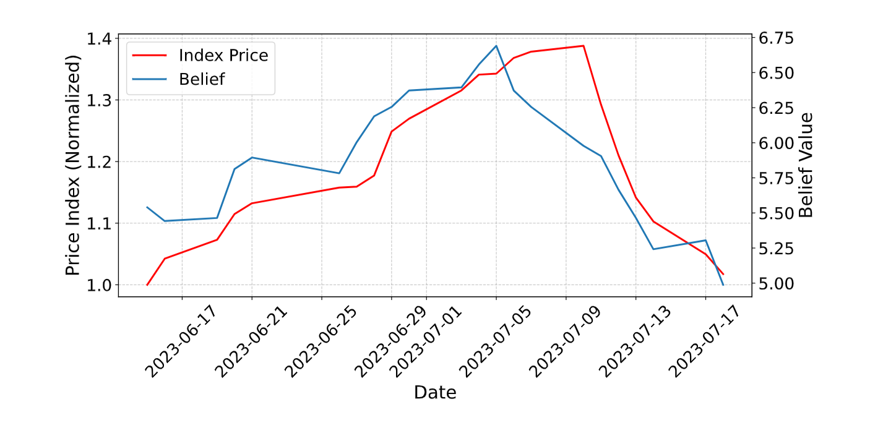

手机 Agent 是更贴近现实交互的一类环境。机器之心关于 PhoneHarness 的报道,把问题放在 OpenAI AI Phone、Gemini on Android 等行业变化之中:如果智能体要真正操作手机,它需要的不只是“看懂屏幕”,还要有混合动作编排、状态追踪与任务执行的 harness。

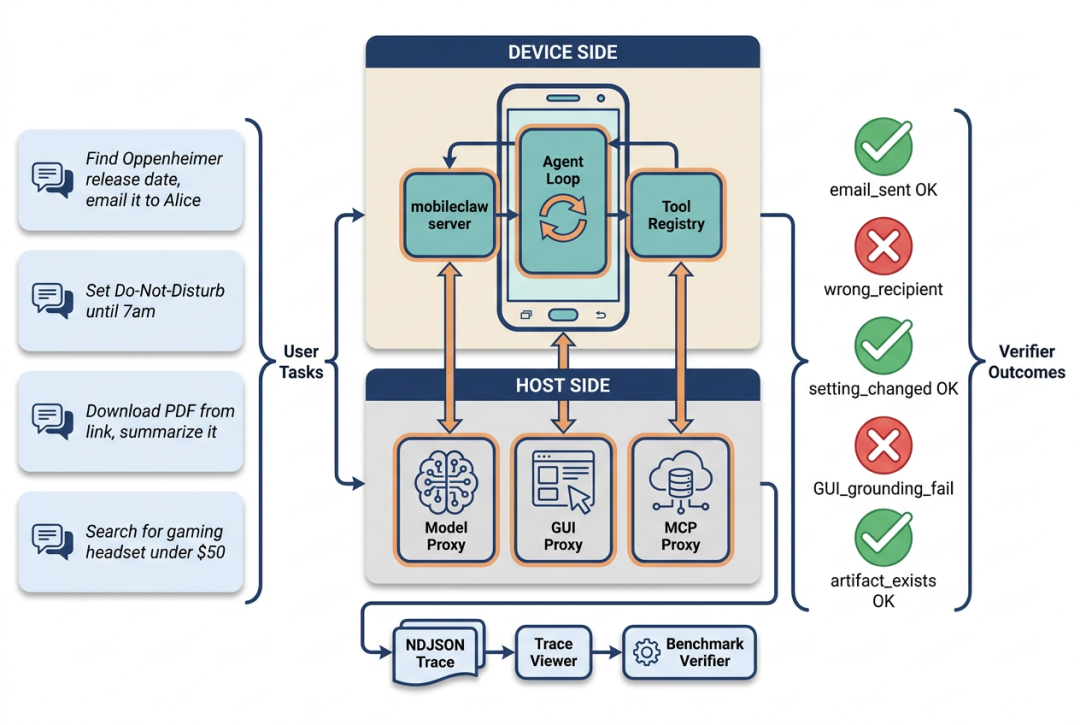
从 TwinMarket 到 MicroVerse,再到 PhoneHarness,我们看到同一个研究问题逐渐清晰:大模型需要可执行、可反馈、可评测的环境,才能从“会生成”走向“会行动”。
Community and Source Index
FreedomAI Lab 的研究会继续围绕开放基础设施展开。我们在 GitHub、Hugging Face 和实验室主页持续发布模型、数据、代码与项目更新,也欢迎对开放医疗智能、多模态模型、Agent 环境和社会模拟感兴趣的同学加入。
GitHub Hugging Face Projects FreedomAI Lab
Media sources
- 机器之心:Phoenix / Chimera 原文。
- 机器之心:HuatuoGPT 原文。
- 机器之心:LongLLaVA 原文。
- 机器之心:TwinMarket 原文。
- 机器之心:MicroVerse 原文。
- 机器之心:PhoneHarness 原文;X 转发记录。
- 量子位:大模型红队攻击与模型对比界面报道;公众号原文。
- PaperWeekly:HuatuoGPT 原文。
- PaperWeekly:LongLLaVA 原文。
- PaperWeekly:CMB 报道链接。
- PaperWeekly:SocraticChat / PlatoLM 报道链接。
- PaperWeekly / AI 求职:李海洲教授 NLP 等方向招生原文。
- PaperWeekly / AI 求职:大语言模型算法实习原文。
- PaperWeekly / AI 求职:王本友 / 李海洲教授 NLP/ML 方向招生报道链接;语音与语言实验室招生报道链接。
- PaperWeekly:2017 年度 NLP 论文 TOP10,IRGAN 入选记录。