Projects项目
No projects found for this tag.
LLM Reasoning & Agentic RL
This project organizes the lab's recent work on verifiable reasoning, policy optimization, path pruning, code-integrated thinking, and multimodal R1-style training. The through-line is simple: make LLMs reason with feedback signals that are inspectable, efficient, and useful for downstream agents.

Paper organization
- OnePO: Direct One-stage Policy Optimization for SFT-free Domain Adaptation - direct policy optimization without a separate SFT stage.
- CRPO: Character-centric Group Relative Policy Optimization for Role-aware Reasoning in Role-playing Agents - RL objectives for role-aware reasoning agents.
- Question-Free Fine-Tuning - efficient and adaptive reasoning fine-tuning.
- Cut Your Losses! Learning to Prune Paths Early for Efficient Parallel Reasoning - learnable path pruning for large reasoning models.
- Video-R1: Reinforcing Video Reasoning in MLLMs - R1-style reinforcement learning for multimodal video reasoning.
- CoRT: Code-integrated Reasoning within Thinking - executable computation inside the reasoning process.
Project stackReasoning papers, code, and datasets
LLM Agents and Applications
This project groups papers where LLMs become agents: tool planners, user simulators, standardized patients, role-playing agents, market participants, and micro-world actors. The goal is to organize agent papers by what the agent does, what environment it acts in, and how the interaction is evaluated.
Paper organization
- Smurfs: Multi-Agent System using Context-Efficient DFSDT for Tool Planning - multi-agent tool planning with context-efficient search.
- Large Language Model as a User Simulator - LLM users for dialogue training and evaluation.
- PlatoLM: Teaching LLMs via a Socratic Questioning User Simulator - Socratic interaction as a training signal.
- Human or LLM as Standardized Patients? - AI patients for medical education and evaluation.
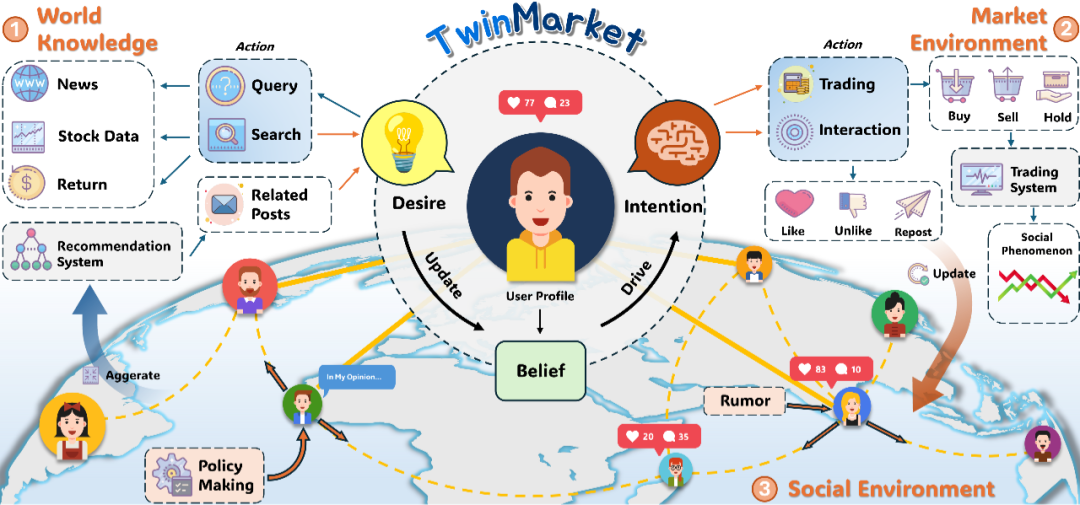
- TwinMarket: A Scalable Behavioral and Social Simulation for Financial Markets - LLM investor agents in market simulation.
- MicroVerse - agentic micro-world simulation for scientific processes.
Project stackAgent applications and environments
Human-Agent Interaction
这条线关注智能体如何和真实用户、学习者、患者、市场参与者以及模拟世界互动。它覆盖 LLM user simulator、AI standardized patients、speech-to-speech human-likeness evaluation、MicroVerse 交互式科学仿真,以及 TwinMarket 这类多智能体社会/金融模拟。
相关论文整理
- Large Language Model as a User Simulator:用 LLM 模拟用户,生成对话训练和评测数据。
- PlatoLM: Teaching LLMs via a Socratic Questioning User Simulator:通过苏格拉底式用户模拟训练多轮对话。
- Human or LLM as Standardized Patients?:医学教育中的 AI 标准化病人。
- Human or Machine? A Preliminary Turing Test for Speech-to-Speech Interaction:语音交互中的人类感评测。
- MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation:面向生物过程和教育可视化的微观世界仿真。
- TwinMarket:金融市场中的行为与社会多智能体仿真。
项目入口Simulation and interaction resources
多模态大模型
多模态大模型方向把文字、图像、视频、音频和医学视觉放进同一个能力地图:从 LongLLaVA/MileBench 的长上下文视觉理解,到 TRIM 的视觉 token 压缩、ShareGPT-4o-Image/Janus-4o 的开放图像生成,再到 Video-R1、HuatuoGPT-Vision 和 FusionAudio 这类面向推理、医疗和音频场景的模型与数据。

相关论文整理
- LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently:长上下文多图像理解和推理。
- MileBench: Benchmarking MLLMs in Long Context:多图像、视频和长视觉上下文评测。
- TRIM: Less is More for Efficient Multi-modal LLMs:减少冗余视觉 token,降低多模态推理成本。
- ShareGPT-4o-Image and Janus-4o:开放 GPT-4o 风格图像生成/编辑数据和统一多模态模型。
- Video-R1: Reinforcing Video Reasoning in MLLMs:把 R1-style reasoning training 扩展到视频理解。
- HuatuoGPT-Vision:面向医学视觉知识注入的多模态医学大模型。
模型 / 数据 / 代码入口Multimodal stack
环境工程和世界模型
这条线把“模型能力”放进可运行环境中:定义状态、行动、工具、用户、规则、世界动力学和评测对齐,让智能体能在用户模拟、金融市场、科学微世界和可执行优化环境中训练、评测和迭代。
相关论文整理
- MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation:把 world model 扩展到器官、细胞和亚细胞过程,强调隐藏机制、状态演化和科学约束。
- TwinMarket: A Scalable Behavioral and Social Simulation for Financial Markets:用 LLM 投资者构造金融市场环境,从个体信念和信息流生成宏观行为。
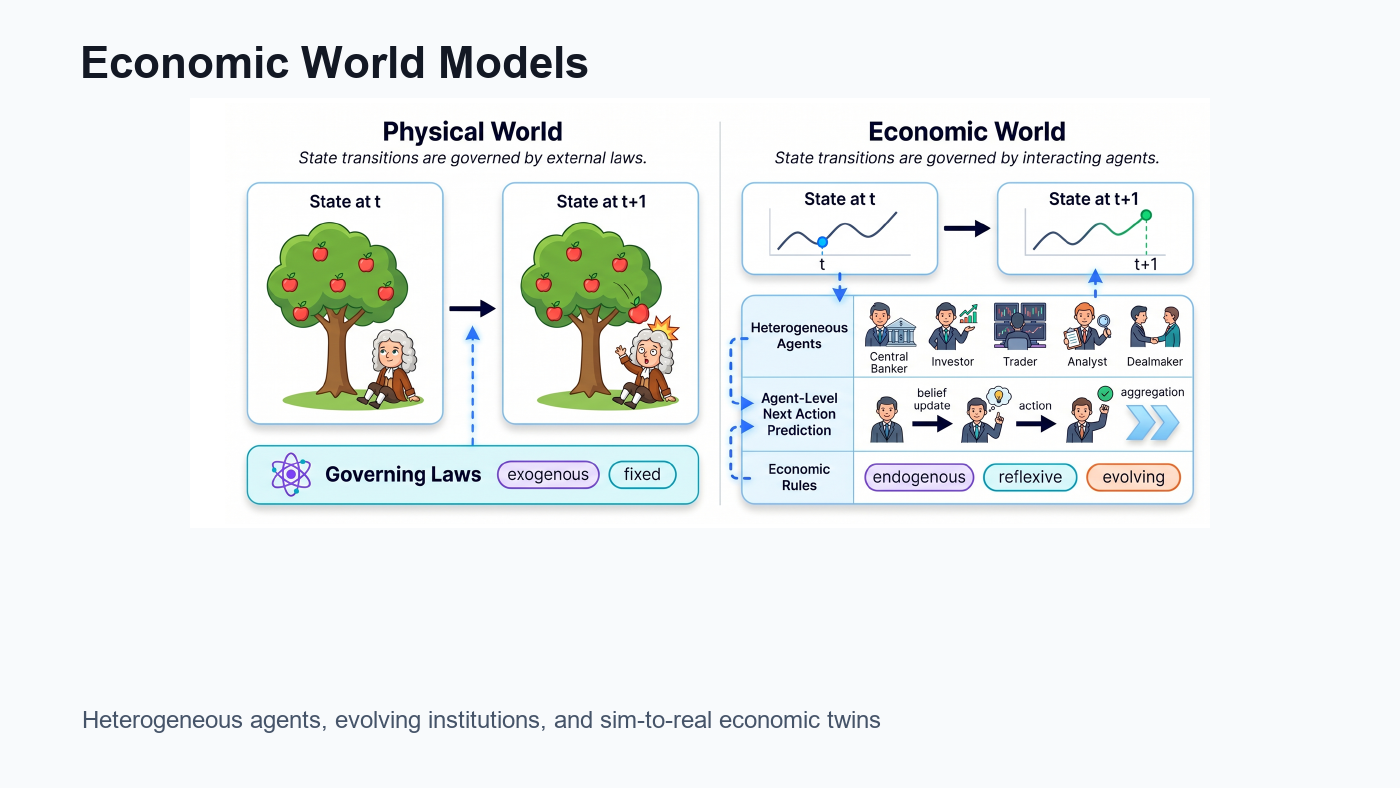
- From Economic Agents to Agentic Economies:把智能体、环境、共演化和真实世界对齐组织成经济世界模型的系统蓝图。
- Large Language Model as a User Simulator:用 LLM 构造可控用户环境,为多轮对话训练和评测提供可重复交互对象。
- ORLM: A Customizable Framework in Training Large Models for Automated Optimization Modeling:把自然语言问题转成优化模型、约束、目标函数和可执行代码。
- CALM Before the STORM:研究优化建模中的原生推理能力,把工程问题组织成可验证建模环境。
项目 / 论文 / 代码资源Environment stack
经济世界模型
经济世界模型把市场、机构、政策和多智能体行为建成可计算、可演化、可对齐的世界。它连接 Economic World Models 的系统蓝图、TwinMarket 的金融市场沙盒、MicroVerse 的科学微世界模拟,以及 Awesome Econ World Models 的文献与资源地图。
相关论文整理
- From Economic Agents to Agentic Economies:提出经济世界模型的系统蓝图,用可计算经济体支持智能体训练、政策沙盒、规划和安全分析。
- TwinMarket: A Scalable Behavioral and Social Simulation for Financial Markets:用 LLM 投资者模拟金融市场中的信念、意图、信息流和交易行为。
- MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation:把 world model 思路扩展到生物与科学微世界,强调隐藏机制和状态演化。
- Awesome Econ World Models:持续整理经济智能体、agentic economies、制度演化、sim-to-real alignment 等方向的论文和资源。
GitHub / Project 资源Paper, repositories, project pages
运筹优化大模型系列
运筹优化主线把自然语言问题转成数学优化模型、约束、目标函数和可执行代码。ORLM 提供开放模型与 IndustryOR benchmark,CALM/STORM 进一步研究优化建模中的原生推理能力。
相关论文整理
- ORLM: A Customizable Framework in Training Large Models for Automated Optimization Modeling:OR-Instruct、ORLM 和 IndustryOR。
- CALM Before the STORM: Unlocking Native Reasoning for Optimization Modeling:优化建模中的原生推理。
- MathScale: Scaling Instruction Tuning for Mathematical Reasoning:数学推理 scaling 与 verifier 相关基础。
- CoRT: Code-integrated Reasoning within Thinking:将代码执行接入思维链,也服务于形式化建模和计算。
GitHub / Hugging Face 资源Code, models, datasets
AI for Healthcare:华佗GPT系列大模型
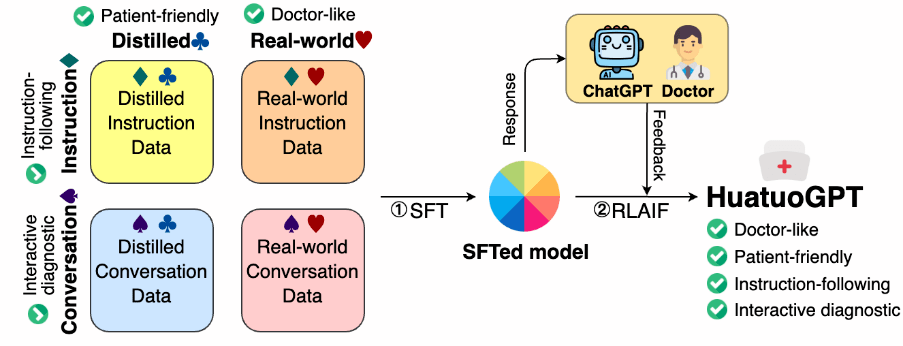
华佗GPT 是 AI for Healthcare 主线:从 Huatuo-26M 中文医学问答数据,到 HuatuoGPT / HuatuoGPT-II 医学适配,再到 HuatuoGPT-o1 的复杂医学推理和 HuatuoGPT-Vision 的医学视觉语言理解。
相关论文整理
- Huatuo-26M, a Large-scale Chinese Medical QA Dataset:中文医学 QA 数据基础。
- HuatuoGPT, towards Taming Language Model to Be a Doctor:早期开放医学对话模型。
- HuatuoGPT-II, One-stage Training for Medical Adaption of LLMs:统一一阶段医学适配训练。
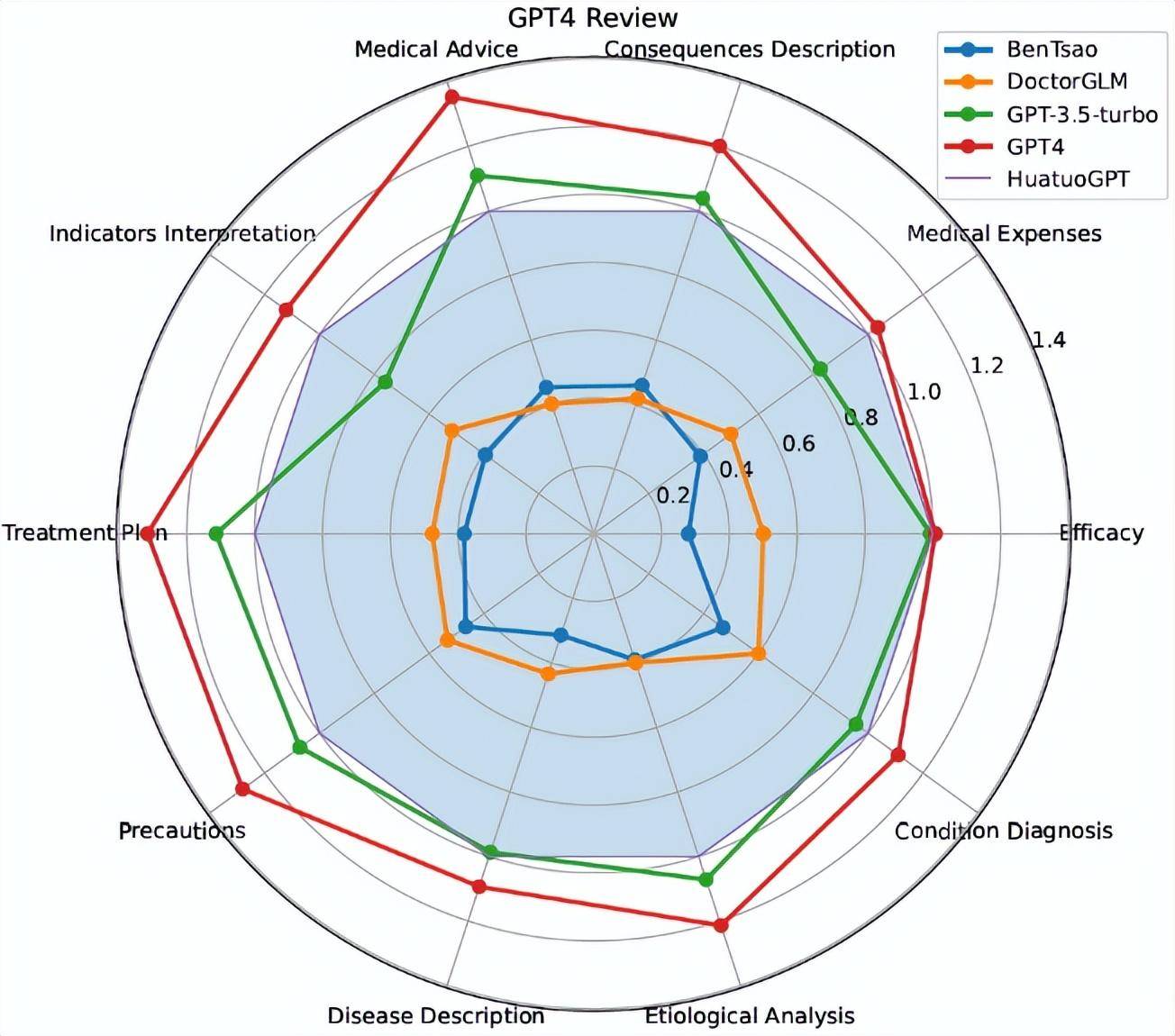
- Towards Medical Complex Reasoning with LLMs through Medical Verifiable Problems:HuatuoGPT-o1 复杂医学推理。
- HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale:医学多模态视觉知识注入。
GitHub / Hugging Face 资源Code, models, datasets
医疗 AI 评测系列
医疗 AI 不能只看聊天流畅度。这条线把评测拆成中文医学知识、多模态医学理解、可解释诊断、实时临床、医生工作流和医学教育几层,让模型在更接近临床的任务上暴露短板。

相关论文整理
- CMB: A Comprehensive Medical Benchmark in Chinese:中文医学综合 benchmark。
- GMAI-MMBench:面向通用医疗 AI 的多模态评测。
- Chain-of-Diagnosis / DxBench:可解释诊断模型和真实医患对话诊断评测。
- LiveClin: A Live Clinical Benchmark without Leakage:持续更新、抗泄漏的真实临床 benchmark。
- Enabling Doctor-Centric Medical AI with LLMs through Workflow-Aligned Tasks and Benchmarks:DoctorFLAN / DotaBench,面向医生工作流。
GitHub / Hugging Face 资源Code, models, datasets
医学教育与 AI 标准化病人
这条线面向医学教育中的 SP(standardized patients)训练,把 AI 病人做成可控、可复用、可评测的练习对象。它同时连接 ACL 医学教育评测与 CHI/人机交互里的共创设计问题:AI 病人不只要“像病人说话”,还要真正帮助学生练习病史采集、沟通和临床推理。
相关论文整理
- Human or LLM as Standardized Patients? A Comparative Study in Medical Education:提出 EasyMED 与 SPBench,对比 AI SP 与人类 SP 的教学效果。
- "It Talks Like a Patient, But Feels Different": Co-Designing AI Standardized Patients with Medical Learners:从 CHI 视角总结医学学习者对 AI SP 的体验和设计需求。
- Doctor-centric workflow-aligned tasks and benchmarks:把医学 AI 评测放进医生真实工作流。
多语言大语言模型
多语言主线从 Phoenix / LLMZoo 的开放多语言聊天开始,到 AceGPT 的阿拉伯语本地化,再到 Apollo / ApolloMoE 的多语言医学模型、语料和评测。核心目标是让医学和通用 AI 不只服务少数高资源语言。
相关论文整理
- Phoenix: Democratizing ChatGPT across Languages:早期开放多语言聊天模型。
- AceGPT, Localizing Large Language Models in Arabic:阿拉伯语大模型本地化与对齐。
- Apollo: Lightweight Multilingual Medical LLMs towards Democratizing Medical AI to 6B People:多语言医学模型、数据和评测。
- ApolloMoE:面向 50 种语言的医学 MoE 模型。
Speech LLMs
Speech LLMs 方向把大模型从文本扩展到语音输入、语音输出、语气、情绪和副语言信息。相关项目包括 Soundwave、S2S-Arena、EchoMind、FusionAudio、UNSPOKEN,以及 speech-to-speech Turing Test。

相关论文整理
- Soundwave: Less is More for Speech-Text Alignment in LLMs:用更少数据完成 speech-text alignment。
- S2S-Arena:评测 speech-to-speech 模型的语义理解和副语言指令跟随。
- EchoMind:面向 empathetic Speech Language Models 的多层级 benchmark。
- Human or Machine? A Preliminary Turing Test for Speech-to-Speech Interaction:评测 S2S 系统是否真正像人类对话。
- FusionAudio-1.2M:细粒度音频 caption 与 multimodal contextual fusion。
- UNSPOKEN:用未说出口的声学线索评测 audio language models 的隐喻推理。
GitHub / Hugging Face 资源Code, models, datasets
LLM efficiency and AI Infra
这条线把“能不能跑得起、训得动、改得快”作为项目主题,覆盖推理路径剪枝、question-free fine-tuning、prefix fine-tuning、editable efficient RAG、长上下文多模态和 token reduction。
相关论文整理
- Cut Your Losses! Learning to Prune Paths Early for Efficient Parallel Reasoning:提前剪枝低价值推理路径。
- Question-Free Fine-Tuning: Towards Efficient and Adaptive Reasoning in Large Language Models:面向高效自适应推理的 QFFT。
- The First Few Tokens Are All You Need:UPFT,用极少前缀 token 进行高效无监督推理微调。
- E2-RAG: Towards Editable Efficient RAG by Editing Compressed KV Caches:编辑压缩 KV cache,面向快速更新场景。
- LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently:长上下文多图像多模态推理。
- TRIM: Less is More for Efficient Multi-modal LLMs:减少视觉 token,降低多模态推理成本。
GitHub / 资源入口Infrastructure stack
LLM Interpretability
可解释性是横向能力:它关心模型为什么这样回答、哪些内部特征真正有用、以及如何把机制理解转成可控编辑。这个方向现在以 sparse autoencoder、model unlearning 和 circuit analysis 为主线,同时连接医学诊断链、verifier 和代码集成推理。

相关论文整理
- Does Higher Interpretability Imply Better Utility? A Pairwise Analysis on Sparse Autoencoders:ICLR 2026,系统比较 SAE 的可解释性指标和实际 steering utility;获 NeurIPS 2025 ResponsibleFM Workshop Outstanding Paper Award。
- Model Unlearning via Sparse Autoencoder Subspace Guided Projections:EMNLP 2025,用 SAE subspace guided projections 做更可控的模型遗忘。
- Towards Understanding Fine-Tuning Mechanisms of LLMs via Circuit Analysis:ICML 2025,用 circuit analysis 理解微调如何改变模型内部计算。
- CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis:用五步诊断链和置信度分布提升医学诊断可解释性。
- Outcome-supervised Verifiers for Planning in Mathematical Reasoning:用结果监督 verifier 辅助数学规划推理。
- CoRT: Code-integrated Reasoning within Thinking:把代码执行放入思维过程,让中间计算更透明。