Medical Evaluation Benchmarks
Benchmark infrastructure for Chinese medical QA, multimodal medical AI, live clinical testing, and doctor workflows.

Medical AI cannot be judged only by generic chat quality. The lab's benchmark work builds domain-specific tests for Chinese medical knowledge, multimodal medical perception, live clinical leakage control, diagnostic reasoning, and doctor-centered workflows.
Evaluation Storyline
It tests whether models know medicine in the language and assessment structure used by Chinese medical education and practice.
Clinical question answering forces models to use patient histories and multi-turn information rather than isolated multiple-choice memory.
Medical AI must combine images, reports, and clinical knowledge, so the benchmark stack expands beyond text-only questions.
Later evaluation directions stress leakage control, diagnostic reasoning, and doctor-centered tasks closer to deployed clinical workflows.
Benchmark Layers
A comprehensive Chinese medical benchmark covering medical exams, clinical QA, and Chinese medical knowledge, with code and Hugging Face data.
A multimodal benchmark for general medical AI, testing whether models can combine medical vision, text, and domain reasoning.
Clinical evaluation directions that reduce leakage risk and stress diagnostic reasoning under more realistic clinical settings.
Doctor-centric evaluation reframes medical AI around tasks clinicians actually perform, rather than only static QA accuracy.
Display Figures
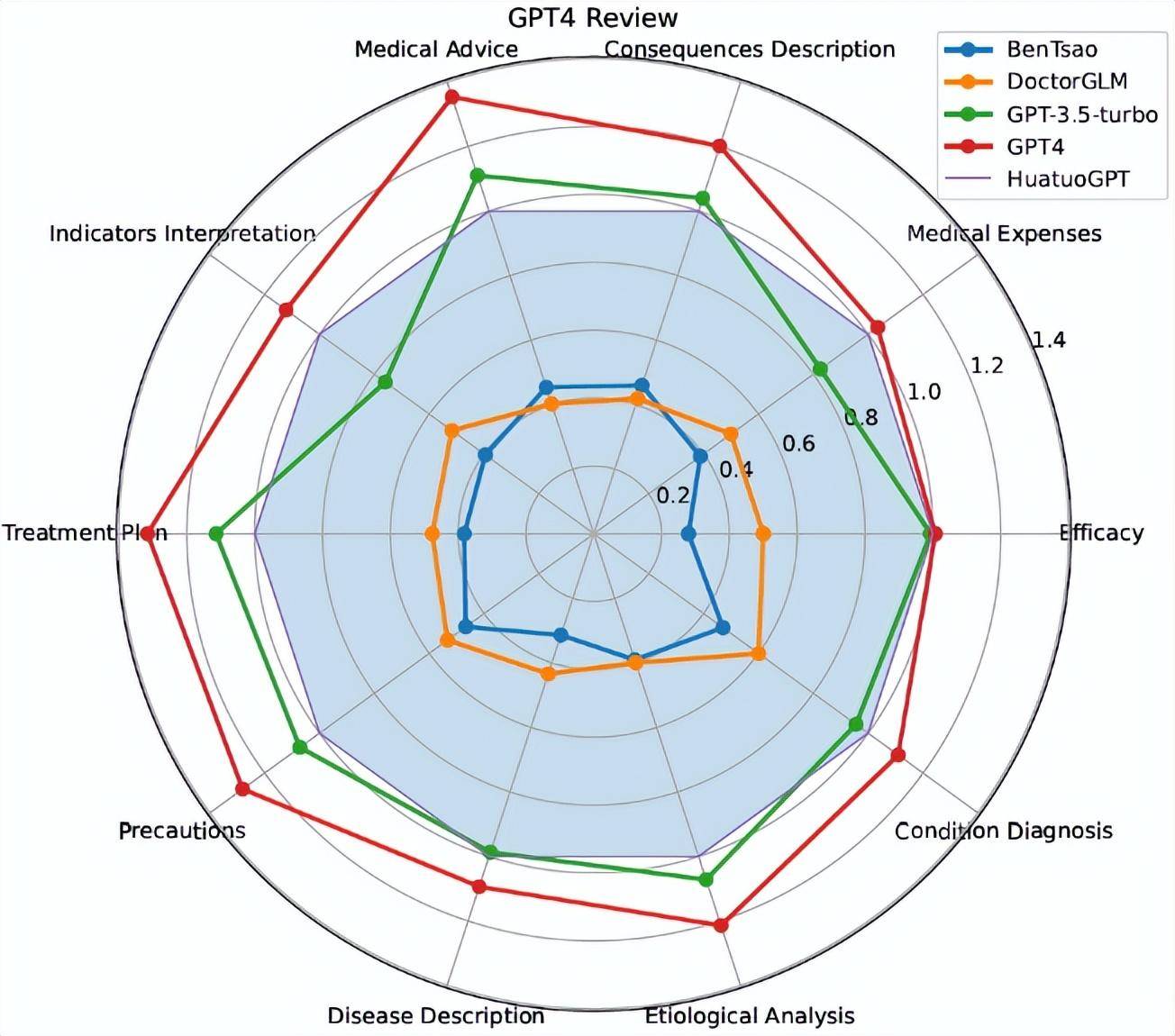
Evaluation Philosophy
Paper Trail
Builds a Chinese medical benchmark with exam and clinical components, giving Chinese medical LLMs a domain-specific yardstick.
RepositoryExtends the evaluation stack to general medical AI scenarios that require multimodal perception and domain reasoning.
Project sitePush medical evaluation toward live, leakage-resistant, diagnostic, and workflow-aligned settings.
LiveClinResource Map
Core Chinese medical benchmark repository and evaluation tooling.
RepositoryHugging Face release for reproducible Chinese medical benchmark experiments.
DatasetMultimodal general medical AI benchmark and public project resources.
Project